Scenario Timeboxing and Time Limits FAQ

Philosophy On Time Limits
Time limits potentially add stress to candidates and aren't a perfect mirror for day-to-day work, so why does Woven use them?
When we started in 2018, we experimented with a mix of timed and untimed scenarios. Over the following years, we saw overwhelming data from customers that turned us into enthusiastic supporters of using well-calibrated timeboxes.
- Timeboxed scenarios are better at predicting success in subsequent interviews and in onboarding. When we looked at correlations between scores and likelhiood of passing subsequent final round technical interviews, timeboxed scenarios had nearly 2x the predictive power.
- Candidates complete timeboxed scenarios at a higher rate. "Do this 90-minute exercise" is more attractive than "most candidates spend 90 minutes" (but there's an implication that some spend much more and maybe you should).
- Timeboxes remove a bias that favors candidates with more time flexibility. Without a timebox, candidates who tended to be younger and more male spent more time and also tended to score higher as a result (when attempting to control for other factors).
Q: What is Woven's philosophy on what makes a scenario timebox well-calibrated?
General principles for evaluating a timebox:
- Shorter is better than longer. Candidate time is precious!
- Distribution of scores should match expectations. We look for a relatively even spread where more-senior benchmarkers (all things equal) tend to score higher.
- It should feel tight, but not too tight for qualified candidates. In the real world, there are time-based tradeoffs. We want to keep those. For some candidates, the timebox will feel unreasonable. For others, it will feel too long.
Q: How do you actually calibrate them?
A: Quantitatively! We calibrate the timebox to be 1/3 more time than the median passing-score, at-seniority-level benchmarker required.
Step 1: Build a scenario prompt that allows candidates to distinguish themselves
When developing a new scenario, we start by iterating on the prompt and testing with outside subject matter experts, Woven customers, and our engineers. We collect feedback with those benchmarks and make adjustments to the prompt and time limit as we build the rubric. We go through several rounds of this testing as we shore up the scenario, working to cut scenario scope down to just the parts that are most-predictive of seniority.
We ask ourselves (among other things) if the signal is strong.
Once we've benchmarked with this group and found the resulting work to have high-enough signal, we calibrate the timebox. Our starting point is typically 33% more time than the median benchmarker took to complete.
Step 2: Calibrate the timebox
We then benchmark with a new group of engineers who haven't seen the scenario before. This is where calibration shifts from more-qualitative to more-quantitative. We look at the resulting scores, results of a feedback form, and completion times. We want to see an even distribution where more senior benchmarkers (all things equal) tend to score higher. We also want to see a mix of low, medium, and high scores.
We also want to see ~20% of qualified candidates who had a high score without needing the entire timebox.
Because we use scores as our primary metric, this is also where we are finalizing the initial scoring rubric.
A given scenario has the same time limit for each customer, because our rubric and scoring are done with the time limit in mind. So if the time limit on this assessment has changed, it would be because the scenarios themselves changed.
Step 3: Launch!
Step 4: Capture data and iterate/refine
Generally, we do a data review as the first ~50 candidates complete, then again after 90 days, and then again after 1000 candidates.
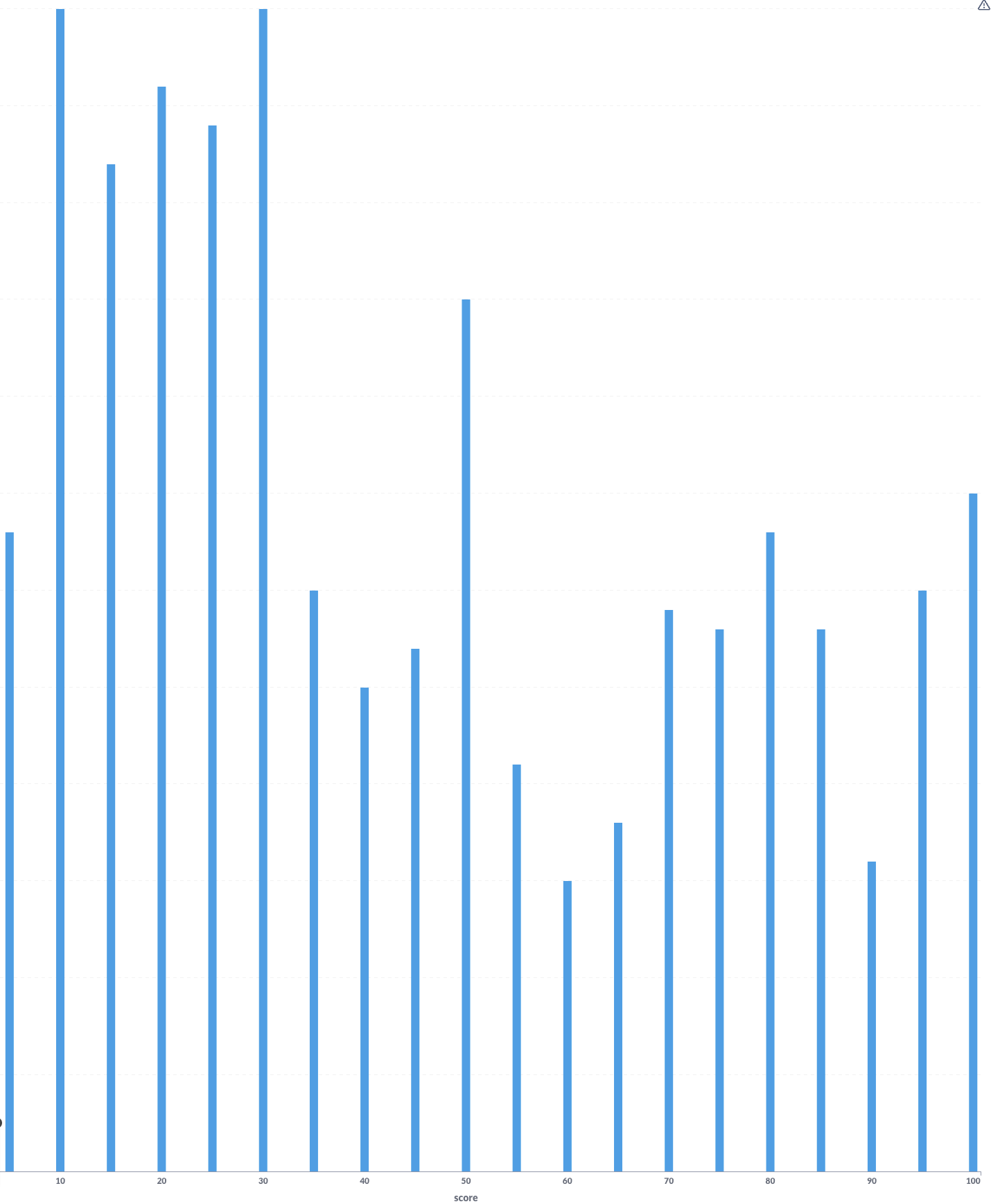
A good old histogram is very useful at this step! This particular histogram shows a scenario that has a wide range and is used for a mix of junior, mid-level, and senior roles. We see a group of scores to the left mostly representing junior-level candidates, and then an even distribution for the rest.
We look at similar criteria as in step 2, but with much more data to work from.
We also look at rubric item improvements for clarity and signal.
Q: What about the overall time limit for an entire assessment (AKA work simulation)?
A: For experienced roles, we recommend 2 hours or under for the overall timebox. That means the sum of the timebox for each individual scenario shouldn't be over 120 minutes without a strong reason.
For entry level or junior roles, it's generally OK to go above 2 hours.
Why 2 hours?
We collected nearly 10k data points with assessments ranging from 30 minutes to 4 hours. Then, we analyzed completion rates for experienced/senior roles.
We found that the completion rate only started to decline once total time was over 2 hours.